Содержание
- 1 Немного про grep
- 2 Описание программ grep
- 3 Базовый синтаксис команды grep
- 4 Как использовать grep для поиска в файлах
- 5 Вызов программы grep
- 6 Справка по команде grep
- 7 Опции grep
- 8 Регулярные выражения
- 9 Переменные окружения grep
- 10 Статус выхода
- 11 Примеры использования grep
- 12 Команда Grep для поиска определенной строки внутри файла
- 13 Количество совпадающих линий
- 14 Инвертирование совпадений в команде Grep
- 15 Строка поиска в стандартном выводе
- 16 Полезные примеры Grep
- 17 Игнорировать регистр
- 18 Как я могу посчитать строку, когда слова совпали
- 19 ДЛЯ ЧЕГО МЫ ПОЛЬЗУЕМСЯ GREP-ОМ?
Немного про grep
Команда grep (global regular expression print) остается одной из наиболее универсальных команд в окружении командной строки Linux. Это происходит потому что grep является чрезвычайно мощной утилитой которая дает пользователям возможность сортировать ввод на основе сложных правил, тем самым делая ее популярным связующим звеном в конвейере команд. Grep в основном используется для поиска текста как в данных поступающих на стандартный вход, так и в указанных файлах на предмет строк содержащих указанные слова или подстроки.
Описание программ grep
grep, egrep, fgrep – печатают строки, соответствующие шаблону.
grep ищет по ШАБЛОНУ в каждом ФАЙЛЕ. ФАЙЛ, обозначенный как «-» является стандартным вводом. Если ФАЙЛ не дан, рекурсивные поиски исследуют рабочую директорию (если рекурсия указана соответствующей опцией), и нерекурсивные поиски считывают стандартный ввод. По умолчанию, grep печатает совпадающие строчки.
В дополнение вариантами программы являются egrep и fgrep, которые являются тем же самым, что и, соответственно, grep -E и grep -F. Варианты egrep и fgrep являются устаревшими, но работают для обратной совместимости. Вместо устаревших вариантов рекомендуется использовать grep -E и grep –F.
В общей сложности имеется четыре варианта grep, различающиеся поддерживаемыми типами регулярных выражений. Они управляются опциями -G (интерпретирует шаблон как базовое регулярное выражение (BRE) – это поведение по умолчанию), -E (интерпретирует шаблон как расширенное регулярное выражение (ERE)), -F интерпретирует шаблон как список фиксированных строк (вместо регулярных выражений), разделённых новой строчкой, любая из которых должна совпасть и -P интерпретирует образец как совместимое с Perl регулярное выражение (PCRE). Последний вариант является экспериментальным, особенно при сочетании с опцией -z (—null-data). «grep -P» может выдать предупреждение о нереализованных функциях – подробности смотрите в секции Остальные опции.
Базовый синтаксис команды grep
Ниже представлены примеры использования grep с базовым синтаксисом:
grep ‘word’ filename grep ‘word’ file1 file2 file3 grep ‘string1 string2’ filename cat otherfile | grep ‘something’ command | grep ‘something’ command option1 | grep ‘data’ grep —color ‘data’ fileName
Как использовать grep для поиска в файлах
Попробуем найти пользователя «vasya» в файле passwd. Для поиска в файле /etc/passwd информации о пользователе «vasya» необходимо использовать следующую команду:
grep vasya /etc/passwd
Пример результата:
vasya:x:1000:1000:vasya,,,:/home/vasya:/bin/bash
Также мы можем попросить grep осуществлять поиск игнорируя регистр букв, то есть не делая различия между большими и маленькими буквами. Для этого используется параметр -i, как показано ниже:
grep -i «vasya» /etc/passwd
Подготовительные работы
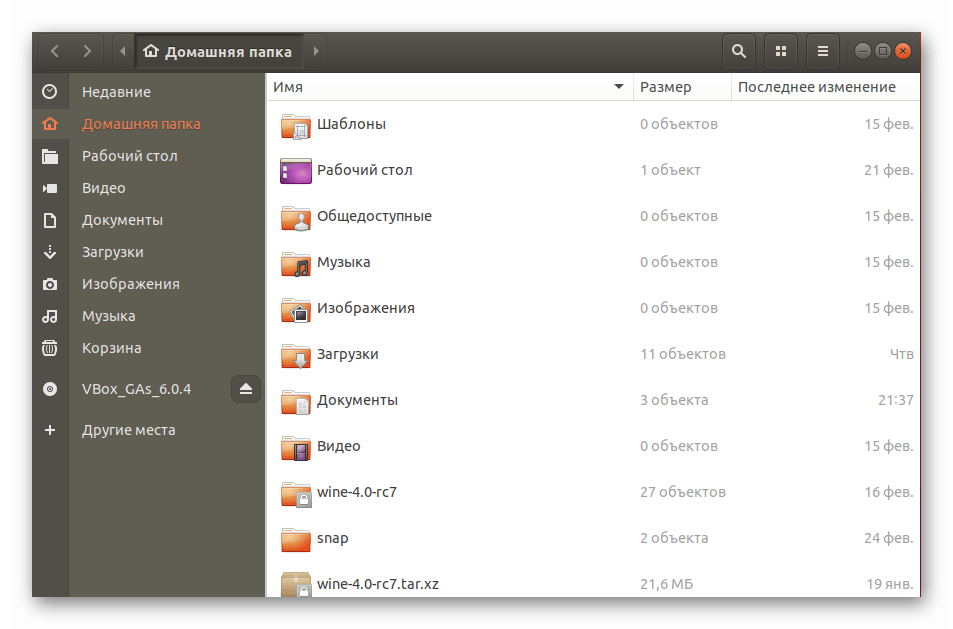
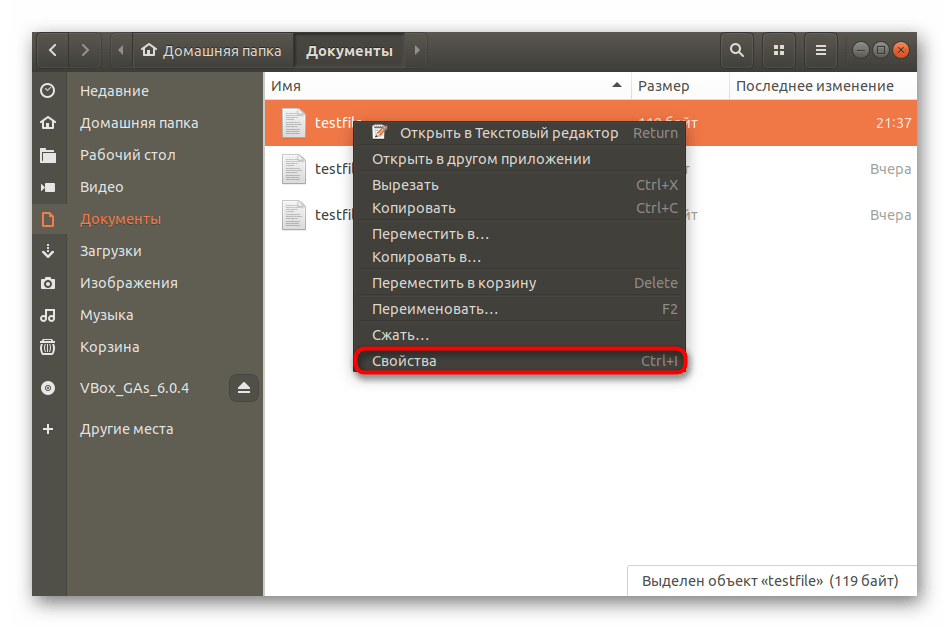
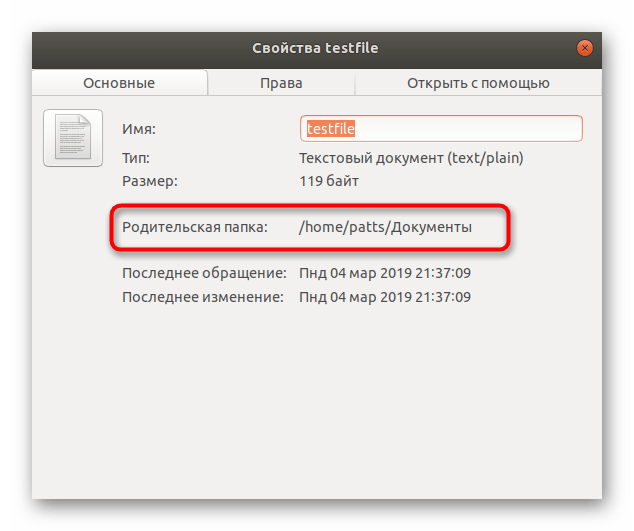
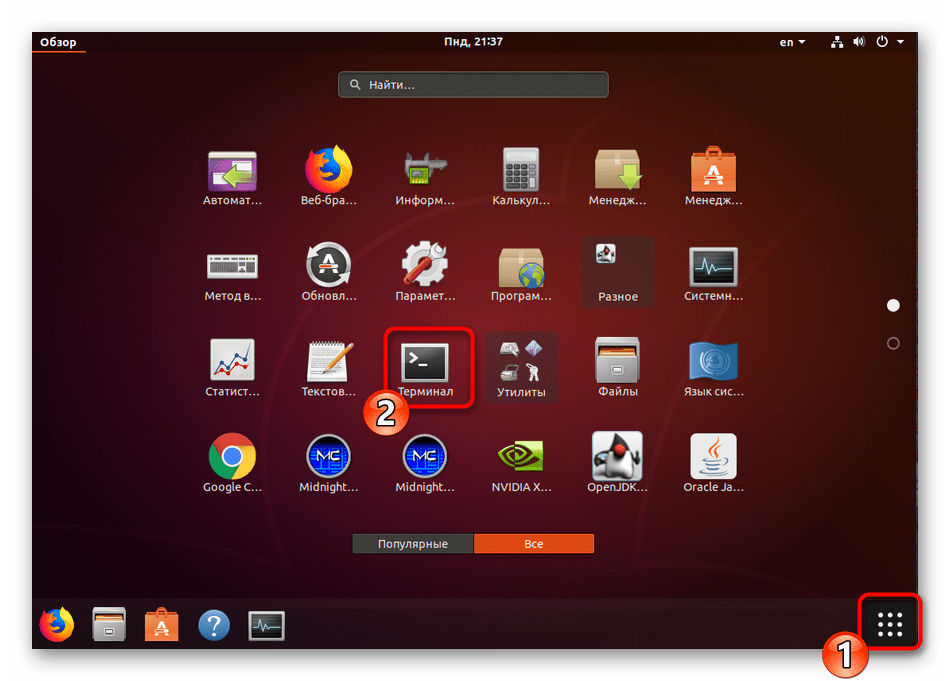
Все дальнейшие действия будут производиться через стандартную консоль, она же позволяет открывать файлы только путем указания полного пути к ним либо если «Терминал» запущен из необходимой директории. Узнать родительскую папку файла и перейти к ней в консоли можно так:
- Запустите файловый менеджер и переместитесь в нужную папку.
- Нажмите правой кнопкой мыши на требуемом файле и выберите пункт «Свойства».
- Во вкладке «Основные» ознакомьтесь со строкой «Родительская папка».
- Теперь запустите «Терминал» удобным методом, например, через меню или зажатием комбинации клавиш Ctrl + Alt + T.
- Здесь перейдите к директории через команду cd /home/user/folder, где user — имя пользователя, а folder — название папки.
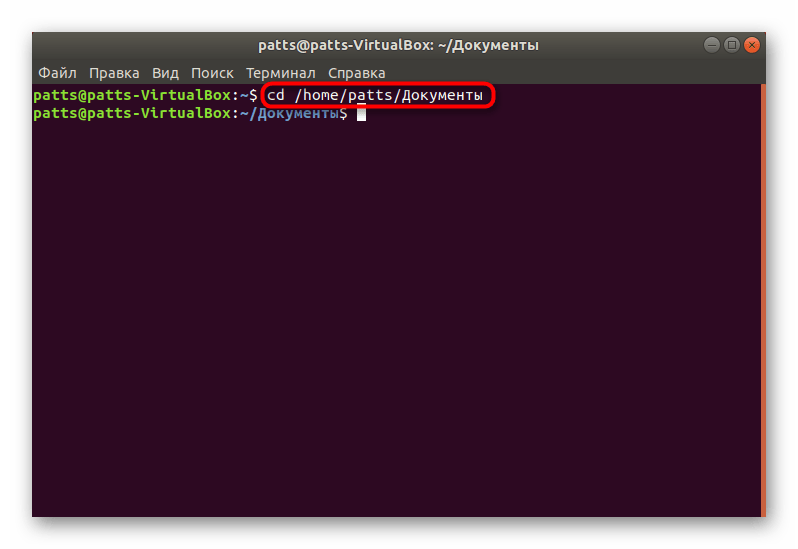
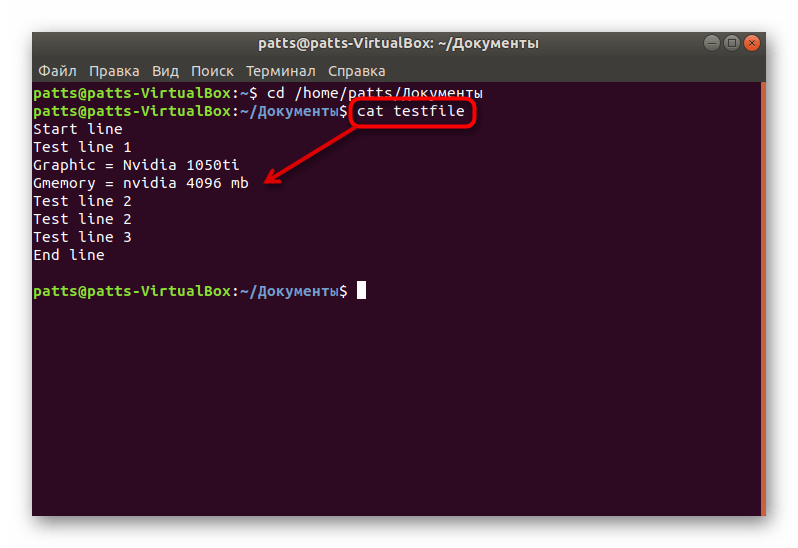
Задействуйте команду cat + название файла, если хотите просмотреть полное содержимое. Детальные инструкции по работе с этой командой ищите в другой нашей статье по ссылке ниже.
Благодаря выполнению приведенных выше действий вы можете использовать grep, находясь в нужной директории, без указания полного пути к файлу.
Стандартный поиск по содержимому
Прежде чем переходить к рассмотрению всех доступных аргументов, важно отметить и обычный поиск по содержимому. Он будет полезен в тех моментах, когда необходимо найти простое совпадение по значению и вывести на экран все подходящие строки.
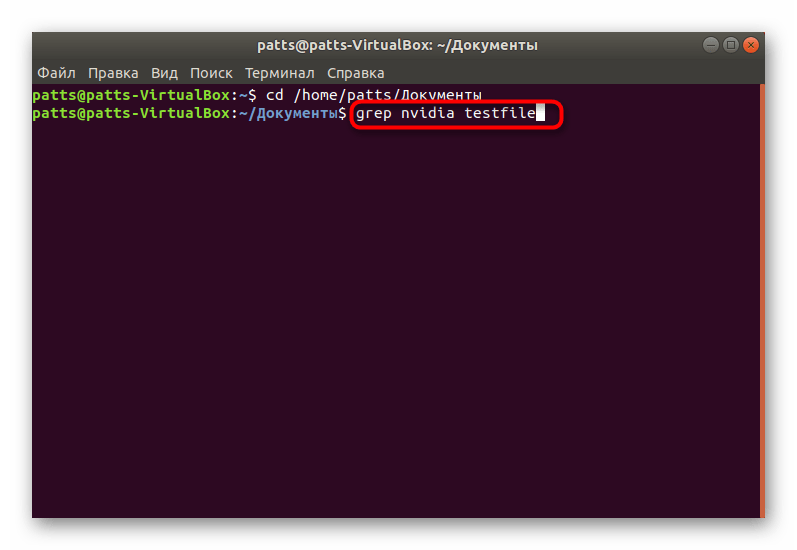
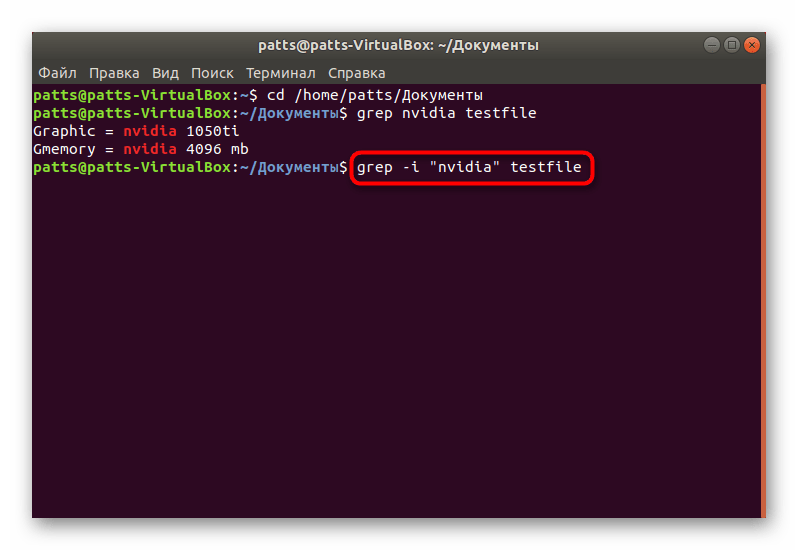
- В командной строке введите grep word testfile, где word — искомая информация, а testfile — название файла. Когда производите поиск, находясь за пределами папки, укажите полный путь по примеру /home/user/folder/filename. После ввода команды нажмите на клавишу Enter.
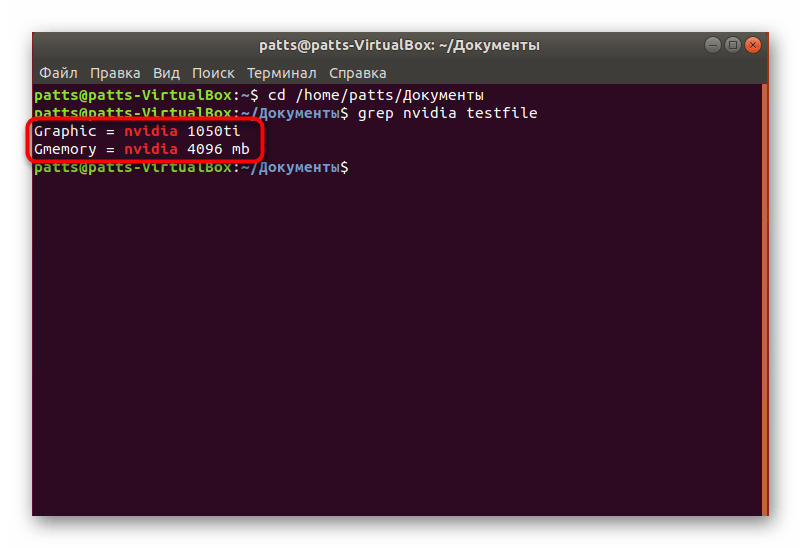
- Осталось только ознакомиться с доступными вариантами. На экране отобразятся полные строки, а ключевые значения будут выделены красным цветом.
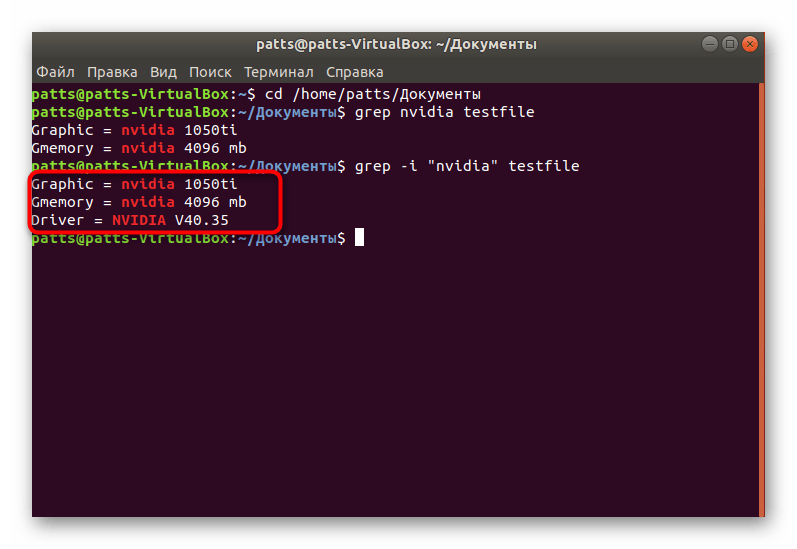
- Важно учитывать и регистр букв, поскольку кодировка Linux не оптимизирована для поиска без учета больших или маленьких символов. Если вы хотите обойти определение регистра, впишите grep -i «word» testfile.
- Как видите, на следующем скриншоте результат изменился и добавилась еще одна новая строка.
Вызов программы grep
Программа grep имеет следующие варианты запуска:
grep [ОПЦИИ] ШАБЛОН [ФАЙЛ…]grep [ОПЦИИ] -e ШАБЛОН… [ФАЙЛ…]grep [ОПЦИИ] -f ФАЙЛ… [ФАЙЛ…]
Может быть ноль или более ОПЦИЙ. ШАБЛОН будет рассматриваться только как таковой (и не как ФАЙЛ) если он ещё не был указан внутри ОПЦИЙ (использованием опций «-e шаблон» или «-f файл»). Может быть указано ноль или более ФАЙЛОВ.
Справка по команде grep
Шаблон выбора и его интерпретация: -E, —extended-regexp ШАБЛОН — расширенное регулярное выражение -F, —fixed-regexp ШАБЛОН — строки, разделённые символом новой строки -G, —basic-regexp ШАБЛОН — простое регулярное выражение (по умолчанию) -P, —perl-regexp ШАБЛОН — регулярное выражения языка Perl -e, —regexp=ШАБЛОН использовать ШАБЛОН для поиска -f, —file=ФАЙЛ брать ШАБЛОН из ФАЙЛа -i, —ignore-case игнорировать различие регистра -w, —word-regexp ШАБЛОН должен подходить ко всем словам -x, —line-regexp ШАБЛОН должен подходить ко всей строке -z, —null-data строки разделяются байтом с нулевым значением, а не символом конца строки Разное: -s, —no-messages не показывать сообщения об ошибках -v, —invert-match выбирать не подходящие строки -V, —version показать информацию о версии и закончить работу —help показать эту справку и закончить работу Управление выводом: -m, —max-count=ЧИСЛО остановиться после указанного ЧИСЛА выбранных строк -b, —byte-offset печатать вместе с выходными строками смещение в байтах -n, —line-number печатать номер строки вместе с выходными строками —line-buffered сбрасывать буфер после каждой строки -H, —with-filename печатать имя файла для каждой выводимой строки -h, —no-filename не начинать вывод с имени файла —label=МЕТКА использовать МЕТКУ в качестве имени файла для стандартного ввода -o, —only-matching показывать только часть строки, совпадающей с ШАБЛОНОМ -q, —quiet, —silent подавлять весь обычный вывод —binary-files=ТИП считать, что двоичный файл имеет ТИП: «binary», «text» или «without-match». -a, —text то же что и —binary-files=text -I то же, что и —binary-files=without-match -d, —directories=ДЕЙСТВ как обрабатывать каталоги ДЕЙСТВИЕ может быть «read» (читать), «recurse» (рекурсивно) или «skip» (пропускать). -D, —devices=ДЕЙСТВ как обрабатывать устройства, FIFO и сокеты ДЕЙСТВИЕ может быть «read» или «skip» -r, —recursive то же, что и —directories=recurse -R, —dereference-recursive тоже, но с переходом по всем символьным ссылкам —include=Ф_ШАБЛОН обработать только файлы, подпадающие под Ф_ШАБЛОН —exclude=Ф_ШАБЛОН пропустить файлы и каталоги, подпадающие под Ф_ШАБЛОН —exclude-from=ФАЙЛ пропустить файлы, подпадающие под шаблон файлов из ФАЙЛА —exclude-dir=ШАБЛОН каталоги, подпадающие под ШАБЛОН, будут пропущены -L, —files-without-match печатать только имена ФАЙЛОВ без выбранных строк -l, —files-with-matches печатать только имена ФАЙЛОВ с выбранными строками -c, —count печатать только количество выбранных строк на ФАЙЛ -T, —initial-tab выравнивать табуляцией (если нужно) -Z, —null печатать байт 0 после имени ФАЙЛА Управление контекстом: -B, —before-context=ЧИС печатать ЧИСЛО строк предшествующего контекста -A, —after-context=ЧИС печатать ЧИСЛО строк последующего контекста -C, —context[=ЧИС] печатать ЧИСЛО строк контекста -ЧИСЛО то же, что и —context=ЧИСЛО —color[=КОГДА], —colour[=КОГДА] использовать маркеры для различия совпадающих строк; КОГДА может быть «always» (всегда), «never» (никогда) или «auto» (автоматически) -U, —binary не удалять символы CR в конце строки (MSDOS/Windows) Если в качестве ФАЙЛА указан символ «-», то читается стандартный ввод. Если ФАЙЛ не указан и задан параметр командной строки -r, то читается текущий каталог «.» и «-» в противном случае. Если указано менее двух ФАЙЛОВ, то предполагается -h. При нахождении совпадений любой строки, кодом завершения программы будет 0, и 1, если ничего не совпало. При возникновении ошибок и если не указан параметр -q, кодом завершения будет 2.
Опции grep
Рассмотрим подробнее опции команды grep.
Общая информация о программе
—help
Вывод справки по использованию с кратким описанием опций команды и адресом для отправки багов, затем выход из программы.
-V, —version
Печатает версию grep в поток стандартного вывода, затем завершает работу. Этот номер версии должен быть включён во все сообщения о багах.
Выбор типа регулярного выражения
-E, —extended-regexp
Интерпретировать ШАБЛОН как расширенное регулярное выражение (ERE, подробности ниже).
-F, —fixed-strings
Интерпретировать ШАБЛОН как список фиксированных строк (вместо регулярных выражений), разделённых символом новой строчки, которые используется для поиска совпадений.
-G, —basic-regexp
Интерпретировать ШАБЛОН как базовое регулярное выражение (BRE, смотрите ниже). Это значение по умолчанию.
-P, —perl-regexp
Интерпретировать ШАБЛОН как совместимое с Perl регулярное выражение (PCRE). Это высоко экспериментальная функция, и grep -P может выводить предупреждение о нереализованных возможностях.
Управление работой регулярных выражений
-e ШАБЛОН, —regexp=ШАБЛОН
Использовать ШАБЛОН как шаблон (образец). Если эта опция используется несколько раз или комбинируется с опцией -f (—file), делается поиск по всем заданным шаблонам. Эта опция может использоваться для защиты шаблона, начинающегося с «-»,
-f ФАЙЛ, —file=ФАЙЛ
Получает образцы из ФАЙЛА, один на строку. Если эта опция используется несколько раз или комбинирована с опцией -e (—regexp), то поиск делается по всем заданным шаблонам. Пустой файл содержит ноль образцов и, следовательно, ничему не будет совпадать.
-i, —ignore-case
Игнорировать различия регистра, т.е. символы, которые различаются только регистром, будут соответствовать друг другу.
Хотя это просто с буквами когда они различаются только регистром – в парах заглавная-прописная буква, поведение является неопределённым в других ситуациях. Например, заглавная «S» во многих локалях имеет необычную контрпару «ſ» (Unicode символ U+017F, LATIN SMALL LETTER LONG S), и не ясно, является ли этот необычный символ соответствием «S» или «s» даже когда перевод из строчной в заглавную приводит к «S».
Другой пример: маленькая германская буква «ß» U+00DF, LATIN SMALL LETTER SHARP S) обычно при переводе в заглавную превращается в двух символьную строку «SS», но она не соответствует «SS» и она может не соответствовать заглавной букве «ẞ» (U+1E9E, LATIN CAPITAL LETTER SHARP S) хотя перевод последней в строчную даёт предыдущую.
-v, —invert-match
Инвертирует (делает противоположным) смысл поиска соответствий, для выбора не-совпадающих строк.
-w, —word-regexp
Выбрать только строки, содержащее соответствие, которое формирует целые слова. Совпадение засчитывается только если совпадающая подстрока окружена символами начала/окончания строчки или неглавными составными символами. Главными составными символами являются буквы, цифры и знак подчёркивания. Эта опция не имеет эффекта, если также указана -x.
-x, —line-regexp
Выбор только тех соответствий, которые совпадают с целой строчкой. Для шаблона регулярного выражения это как если бы образец взяли в круглые скобки и затем окружили ^ и $.
-y
Абсолютный синоним для -i, предоставляется для совместимости.
Управление выводом
-c, —count
Подавляет нормальный вывод; вместо него печатает количество совпавших строк для каждого введённого файла. С опцией -v, —invert-match (смотрите ниже), считает несовпадающие строки.
—color[=КОГДА], —colour[=КОГДА]
Окружает подходящие (не пустые) строки, соответствующие строчки, строчки контекста, имена файлов, номера строк, байтные сдвиги и разделители (для полей и групп контекстных строчек) управляющими последовательностями для отображения их в цвете на терминале. Цвета определены переменной окружения GREP_COLORS и значениями по умолчанию это «ms=01;31:mc=01;31:sl=:cx=:fn=35:ln=32:bn=32:se=36», т.е. это полужирный красный для подходящего текста, пурпурный для имён файлов, зелёный для номеров строк, зелёный для байтового сдвига, циан для разделителей, и стандартные цвета терминала для другого. Всё ещё поддерживается устаревшая переменная окружения GREP_COLOR, но её настройки не имеют приоритета; её значением по умолчанию является «01;31» (полужирный красный) который охватывает только цвет для совпадающего текста. КОГДА может иметь значение never, always или auto.
-L, —files-without-match
Подавляет нормальный вывод; вместо него печатает имя каждого файла, в котором не найдено ни одного совпадения (по умолчанию эти файлы бы не дали никакого вывода). Сканирование (конкретного файла) остановится при первом совпадении.
-l, —files-with-matches
Подавляет нормальный вывод; вместо него печатает имя для каждого файла ввода, в котором найдено совпадение. Сканирование (конкретного файла) остановится при первом найденном совпадении.
-m ЧИСЛО, —max-count=ЧИСЛО
Остановить чтение файла после ЧИСЛА совпадающих строк. Если вводом является стандартный ввод из регулярного файла, и выведено ЧИСЛО совпадающих строк, перед выходом grep убеждается, что стандартный ввод указывает на место сразу после последней совпавшей строки, независимо от наличия идущих сзади контекстных строк. Это даёт возможность вызывающему процессу возобновить поиск. Например, следующий шелл скрипт использует это:
while grep -m 1 PATTERN do echo xxxx done < FILE
Но следующий вероятно не будет работать, поскольку труба не является регулярным файлом:
# Вероятно не будет работать. cat FILE | while grep -m 1 PATTERN do echo xxxx done
Когда grep останавливается после ЧИСЛА совпавших строк, он выводит идущие сзади контекстные строки. Поскольку контекст не включает совпадающие строки, grep остановится, когда встретит другую совпадающую строку. Когда также используется опция -c или —count, grep не выводит счётчик выше чем ЧИСЛО. Когда также используется опция -v или —invert-match, grep останавливается после вывода ЧИСЛА несовпадающих строк.
-o, —only-matching
Печатает только совпадающие (не пустые) части совпавшей строки, по каждой такой части на отдельной строчке. Выведенные строки используют тот же разделитель, что и ввод, и разделители являются null-байтами, если также используется -z (—null-data) (смотри секцию Остальные опции).
-q, —quiet, —silent
Тишина; не писать что-либо в стандартный вывод. Выход немедленно со статусом ноль, если найдено любое совпадение, даже если была обнаружена ошибка. Также смотрите опции -s или —no-messages.
-s, —no-messages
Подавляет сообщения об ошибках о несуществующих или нечитаемых файлах.
Управление префиксом выходной строки
-b, —byte-offset
Печатает 0-байтное смещение внутри файла ввода перед каждой строкой вывода. Если указана -o (—only-matching), печатает смещение самой совпадающей части. Когда grep запущена на MS-DOS или MS-Windows, выводимый байтовый сдвиг зависит от использования опции -u (—unix-byte-offsets); смотрите ниже.
-H, —with-filename
Печатать имя файла для каждого соответствия. Это значение по умолчанию, когда делается поиск по более чем одному файлу.
-h, —no-filename
Подавляет добавление префикса к имени файла в выводе. Это опция по умолчанию, когда только один файл для поиска (или только стандартный ввод).
—label=МЕТКА
Показывает ввод, в действительности пришедший из стандартного ввода, как пришедший из файла МЕТКА. Это особенно полезно когда выполняются инструменты вроде zgrep, к примеру, что-то вроде:
gzip -cd foo.gz | grep —label=foo -H
Также смотрите опцию -H.
-n, —line-number
Предваряет каждую строку вывода номером строки из файла ввода.
-T, —initial-tab
Убедитесь, что первый символ фактического содержимого строки расположен на табуляции, чтобы выравнивание табуляций выглядело нормально. Это полезно с опциями, которые добавляют префикс к их фактическому содержимому: -H,-n и -b. Чтобы увеличить вероятность того, что строки из одного файла будут все начинаться с той же колонки, номера строки и байтового сдвига (если есть) будут выведены на поле минимальной ширены.
-u, —unix-byte-offsets
Печатать вместе с строками вывода смещение в байтах в стиле Unix. Этот переключатель приводит к тому, что grep выводит байтовое смещение так, как если бы это был текстовый файл в стиле Unix, т.е. с обрезанными символами CR. Это произведёт результат идентичный запуску grep на Unix машине. Эта опция не имеет эффекта, если также не используется опция -b; она не имеет эффекта на платформах отличных от MS-DOS и MS-Windows.
-Z, —null
Вывод нулевого байта (символа ASCII NUL) вместо символа, который обычно следует за именем файла. Например grep -lZ выводит нулевой байт после каждого имени файла вместо обычной новой строки. Эта опция делает вывод недвусмысленным, даже в присутствии имени файлов необычных символов вроде новой строки, вроде новой строки. Эта опция может использоваться с командами вроде find -print0, perl -0, sort -z и xargs -0 для обработки произвольных файловых имён, даже тех, которые содержат символы новой строки.
Управление контекстными строками
Контекстные строки – это не совпавшие строки, которые находятся около совпавшей строки. Они выводятся только если используется одна из следующих опций. Независимо как эти опции установлены, grep никогда не выводит любую заданную строку более чем единожды. Если указана опция -o (—only-matching), эти опции не имеют эффект и во время их использования будет дано предупреждение.
-A ЧИСЛО, —after-context=ЧИСЛО
Печатает ЧИСЛО строк последующего контекста после совпадающих строк. Размещает строку, содержащую разделитель (—), между смежными группами соответствий. С опцией -o или —only-matching это не имеет эффекта и выдаётся предупреждение.
-B ЧИСЛО, —before-context=ЧИСЛО
Печатает ЧИСЛО строк предшествующего контекста перед совпавшей строкой. Помещает строку, содержащую разделитель (—) между смежными группами соответствий. С опцией -o или —only-matching это не имеет эффекта и выдаётся предупреждение.
-C ЧИСЛО, -ЧИСЛО, —context=ЧИСЛО
Печатает ЧИСЛО строк предшествующего и последующего контекста после совпадающих строк. Помещает строку, содержащую разделитель (—) между смежными группами соответствий. С опцией -o или —only-matching это не имеет эффекта и выдаётся предупреждение.
Выбор файлов и директорий
-a, —text
Обрабатывать бинарный файл будто бы это текстовый; это эквивалент опции —binary-files=text.
—binary-files=ТИП
Если данные файла или метаданные говорят о том, что файл содержит бинарную информацию, предполагается, что это файл типа ТИП. Не-текстовые байты говорят о бинарных данных; это либо вывод байтов, которые неправильно кодированы для текущей локали (смотрите Переменные окружения), или null-байты ввода, когда указана опция -z (—null-data) (смотрите Остальные опции).
По умолчанию ТИП это «binary», и когда grep обнаруживает, что файл является бинарным, она подавляет любой последующий вывод и вместо этого выводит либо сообщение в одну строку, говорящее о совпадениях бинарного файла, или сообщение, что совпадений нет.
Если ТИП это «without-match», когда grep обнаруживает, что файл является бинарным, то программа предполагает, что оставшаяся часть файла не совпадает; это эквивалент опции -I.
Если ТИП это «text», grep обрабатывает бинарный файл так, как если бы он был текстовым; это эквивалент опции -a.
Когда ТИП это «binary», grep может обрабатывать не-текстовые байты как разделители строк, даже без опции -z (—null-data). Это означает, что выбор «binary» или «text» может определить, будут ли в файле совпадения шаблону. Например, когда ТИП это «binary» шаблон «q$» может соответствовать «q» за которым сразу идёт null-байт, даже хотя это не соответствует, когда ТИП является «text». Наоборот, когда ТИП это «binary», шаблон «.» (точка) может не соответствовать null-байту.
Предупреждение: опция -a (—binary-files=text) может выводить бинарный мусор, который может иметь неприятные сторонние эффекты если вывод делается в терминал и если терминальный драйвер интерпретирует некоторую его часть как команды. С другой стороны, при чтении файлов, чья кодировка неизвестна, может быть полезно использовать -a или установить в окружении LC_ALL=’C’ чтобы найти больше соответствий даже если совпадения небезопасны для непосредственного отображения.
-D ДЕЙСТВИЕ, —devices=ДЕЙСТВИЕ
Если файлом ввода является устройство, FIFO или сокет, использовать ДЕЙСТВИЕ для его обработки. По умолчанию, ДЕЙСТВИЕ – это «read», что означает, что устройства читаются как если бы они были обычными файлами. Если ДЕЙСТВИЕ это «skip», устройства тихо пропускаются.
-d ДЕЙСТВИЕ, —directories=ДЕЙСТВИЕ
Если файл ввода является директорией, использовать ДЕЙСТВИЕ для его обработки. По умолчанию ДЕЙСТВИЕ это «read», т.е. читать директории как если бы они были обычными файлами. Если ДЕЙСТВИЕ это «skip», тихо пропускать директории. Если ACTION это «recurse», то рекурсивно считывать все файлы в каждой директории, следовать символическим ссылкам только если они в командной строке и пропускать если они встретились рекурсивно. Это эквивалент опции -r.
—exclude=Ф_ШАБЛОН
Пропустить любой файл командной строки с суффиксом имени, который соответствует образцу Ф_ШАБЛОН, в котором можно использовать подстановочные символы; суффикс имени – это либо всё имя, либо любой суффикс начинающийся после / и перед +non-/. При рекурсивном поиске, пропускать любые субфайлы, чьё имя соответствует Ф_ШАБЛОН; базовое имя – это часть после последнего /. Шаблон может использовать в качестве подстановочных символов *, ? и […], и для передачи подстановочных символов или обратных слешей в качестве буквальных символов.
—exclude-from=ФАЙЛ
Пропустить файлы, чьё базовое имя соответствует любому из Ф_ШАБЛОНОВ, считанных из ФАЙЛА (использование подстановочных символов соответствует описанному для опции —exclude).
—exclude-dir= Ф_ШАБЛОН
Пропускать любую директорию командной строки с суффиксом имени, который соответствует образцу Ф_ШАБЛОН. При рекурсивном поиске, пропускать любую субдиректорию, чьё базовое имя соответствует Ф_ШАБЛОН. Игнорировать любые избыточные конечные слеши в Ф_ШАБЛОНЕ.
-I
Обрабатывать бинарный файл, как если бы он не содержал подходящих данных; это эквивалент опции —binary-files=without-match.
—include=Ф_ШАБЛОН
Искать только в файлах, чьё базовое имя соответствует Ф_ШАБЛОН (использование подстановочных символов соответствует описанному для опции —exclude).
-r, —recursive
Рекурсивно считывать все файлы в каждой директории, следуя символьным ссылкам только если они в командной строке и пропускать, если они встретились рекурсивно. Помните, если не дан файловый операнд, grep ищет по рабочей директории. Это эквивалент опции -d recurse.
-R, —dereference-recursive
Рекурсивно считывать все файлы в каждой директории. В отличие от -r следовать всем символическим ссылкам.
Остальные опции
—line-buffered
Использовать буферизацию строк. Это может ухудшить производительность.
-U, —binary
Обрабатывать файл(ы) как бинарный. По умолчанию, в MS-DOS и MS-Windows grep угадывает, является ли файл текстовым или бинарным как это описано в разделе опции —binary-files. Если grep решает, что файл является текстовым файлом, программа из оригинального содержимого файла отбрасывает символы CR (чтобы регулярные выражения с ^ и $ правильно работали). Указание -U аннулирует правило догадки, приводя к тому, что все файлы считываются и передаются к буквальному механизму поиска совпадений; если файл является текстовым с парами CR/LF на конце каждой строки это приведёт к неудачи некоторых регулярных выражений. Эта опция не имеет эффекта на платформах отличных от MS-DOS и MS-Windows.
-z, —null-data
Трактовать данные ввода и вывода как последовательность строк, каждая вместо символа «новая строка» отделяется нулевым байтом (символ ASCII NUL). Как опция -Z или —null, эта опция может использоваться с командами вроде sort -z для обработки произвольных имён файлов.
Регулярные выражения
Регулярное выражение – это шаблон, который описывает набор строк. Регулярные выражения конструируются аналогично арифметическим выражениям с использованием различных операторов для комбинирования более маленьких выражений.
Программа grep понимает три различных типа синтаксисов регулярных выражений: «basic» (BRE), «extended» (ERE) и «perl» (PCRE). В GNU grep нет разницы в доступной функциональности между базовым «basic» и расширенным синтаксисами «extended». В других реализациях, базовые регулярные выражения менее мощные. Последующее описание применимо к расширенным регулярным выражениям; отличия для базовых регулярных выражений подытожены в конце. Совместимые с Perl регулярные выражения дают дополнительную функциональность, они документированы в pcresyntax(3) и pcrepattern(3), но работают только если в системе доступен PCRE.
Фундаментальная структура
Основными строительными блоками являются регулярные выражения, которые соответствуют единичному символу. Большинство символов, включая все буквы и цифры, являются регулярными выражениями, которые соответствуют самим себе. Любой метасимвол со специальным значением может использоваться в буквальном их значении, если перед ним поставить обратный слеш.
Точка . соответствует любому единичному символу.
Пустое регулярное выражение соответствует пустой строке.
Классы символов и Выражения в квадратных скобках
Выражение в квадратных скобках – это набор символов, заключённых в [ и ]. Оно совпадает с любым единичным символом в этом списке; если первым символом этого списка является каретка ^, то оно совпадает с любым символом, не из этого списка. Например, следующее регулярное выражение совпадает с любой единичной цифрой [0123456789]
Внутри квадратных скобок выражение диапазона состоит из двух символов, разделённых тире. Этот диапазон совпадает с любым символом, который сортируется между этими двумя символами (с использованием последовательности сортировки локали и набора символов), включая их самих. Например, в C локали по умолчанию [a-d] эквивалентно [abcd]. Многие локали сортируют символы в словарном порядке, и в этих локалях [a-d] обычно не эквивалентно [abcd]; это может быть, к примеру, эквивалентом [aBbCcDd]. Для получения традиционной интерпретации выражений в квадратных скобках вы можете использовать C локаль установив переменную окружения LC_ALL на значение C.
Наконец, определённые именованные классы символов предопределены внутри выражений в квадратных скобках как показано ниже. Их интерпретация зависит от LC_CTYPE локали; например, «[[:alnum:]]» означает класс символов из чисел и букв в текущей локали.
[:alnum:]
Алфавитные символы: «[:alpha:]» и «[:digit:]»; в локали «C» и кодировке символов ASCII, это то же самое что и «[0-9A-Za-z]».
[:alpha:]
Алфавитные символы: «[:lower:]» и «[:upper:]»; в локали «C» и кодировке символов ASCII, это то же самое что и «[A-Za-z]».
[:blank:]
Пустые символы: пробел и табуляция.
[:cntrl:]
Управляющие символы. В ASCII эти символы имеют восьмеричные коды от 000 до 037 и 177 (DEL). В других наборах символов это эквивалентные символы, если они есть.
[:digit:]
Цифры: 0 1 2 3 4 5 6 7 8 9.
[:graph:]
Графические символы: «[:alnum:]» и «[:punct:]».
[:lower:]
Буквы в нижнем регистре, в локали «C» и кодировке символов ASCII это a b c d e f g h i j k l m n o p q r s t u v w x y z.
[:print:]
Печатные символы: «[:alnum:]», «[:punct:]», и пробел.
[:punct:]
Пунктуационные символы; в локали «C» и кодировке символов ASCII, это ! » # $ % & ‘ ( ) * + , — . / : ; < = > ? @ [ ] ^ _ ` { | } ~.
[:space:]
Пробельные символы: в локали «C», это табуляция, новая строка, вертикальная табуляция, разрыв страницы, возврат каретки и пробел. Смотрите раздел Использование grep для дополнительной информации о совпадении новой строки.
[:upper:]
Буквы в верхнем регистре: в локали «C» и кодировке символов ASCII, это A B C D E F G H I J K L M N O P Q R S T U V W X Y Z.
[:xdigit:]
Шестнадцатеричные цифры: 0 1 2 3 4 5 6 7 8 9 A B C D E F a b c d e f.
Обратите внимание, что квадратные скобки в этих классах имён являются частью символических имён и должны быть включены в дополнение к квадратным скобкам, отделяющим выражения в квадратных скобках.
Большинство метасимволов теряют их специальное значение внутри выражений в квадратных скобках. Для включения буквального ] разместите его первым в списке. Аналогично литерал ^ разместите где-угодно, но только не первым. Наконец, для включения литерала — разместите его последним.
]
если не является первым пунктом, завершает выражение в квадратных скобках. Поэтому если вы хотите сделать символ «]» элементом списка, вы должны поставить его в начало.
[.
обозначает открывающий символ сортировки
.]
обозначает закрывающий символ сортировки
[=
представляет открытие класса эквивалентности.
=]
представляет закрытие класса эквивалентности.
[:
представляет открывающий символ класса символов, за ним должно следовать действительное имя класса символов.
:]
представляет закрывающий символ класса символов.
—
представляет диапазон если не является первым или последним в списке или конечной точкой диапазона.
^
представляет символы не включаемые в список. Если вы хотите сделать символ ^ элементом списка, разместите её где-угодно кроме первой позиции.
Анкоры
Каретка ^ и знак доллара $ являются метасимволами, которые представляют, соответственно, начало и конец строки. Они называются анкорами (буквально «якоря»), поскольку принудительно «якорят» совпадение, соответственно, к началу или концу строки.
Символы с обратным слешем и Специальные выражения
Символ , когда за ним следует определённые обычные символы, принимает специальное значение:
b
Обозначает край слова.
B
Обозначает не край слова.
<
Обозначает начало слова.
>
Обозначает конец слова.
w
Обозначает главные составные символы, это синоним для «[_[:alnum:]]».
W
Обозначает не главные составные символы, это синоним для «[^_[:alnum:]]».
s
Обозначает белые пробелы, это синоним для «[[:space:]]».
S
Обозначает не белые пробелы, это синоним для «[^[:space:]]».
Например, «bratb» совпадает с отделённым словом «rat», «BratB» совпадает с «crate», но не с «furry rat».

Повторения
За регулярным выражением может следовать один или несколько операторов повторения:
?
Предыдущий элемент опциональный (встречается ноль или один раз).
*
Предыдущий элемент встречается ноль или более раз.
+
Предыдущий элемент встречается один или более раз
{n}
Предыдущий элемент встречается ровно n раз.
{n,}
Предыдущий элемент встречается n или более раз.
{,m}
Предыдущий элемент встречается не более m раз.
{n,m}
Предыдущий элемент встречается по крайней мере n раз, но не более чем m раз.
Объединение регулярных выражений
Два регулярных выражения могут быть объединены; результирующее регулярное выражение соответствует любой строке, сформированной объединением двух подстрок, каждая из которых соответственно соответствует двум объединённым выражениям.
Альтернативы в регулярных выражениях
Два регулярных выражения могут быть объединены оператором |
Результирующее регулярное выражение совпадает с любой строкой, соответствующей одному из альтернативных выражений.
Приоритет
Повторение имеет приоритет над объединением, которое, в свою очередь, имеет приоритет над альтернативой. Целое регулярное выражение может быть заключено в круглые скобки для перезаписи этих правил приоритетов и формирования подвыражения.
Обратные ссылки и Подвыражения
Обратная ссылка n, где n это единичная цифра, соответствует подстроке, совпавшей ранее с n-ным подвыражением регулярного выражения, заключённым в круглые скобки. Например, «(a)1» соответствует «aa». Когда используется альтернатива, если группа не принимает участие в совпадении, то обратная ссылка делает всё совпадение неудавшимся. Например, «a(.)|b1» не будет соответствовать «ba». Когда с опцией -e или из файла («-f file») дано несколько регулярных выражений, обратная ссылка является локальной для каждого выражения.
Базовые и расширенные регулярные выражения
В базовых регулярных выражениях метасимволы ?, +, {, |, (, и ) теряют их специальное значение; вместо них используйте версии с обратным слешем ?, +, {, |, (, и ).
Традиционная egrep не поддерживает метасимвол «{», а некоторые реализации egrep поддерживают вместо этого «{», поэтому портативные скрипты должны избегать «{» в шаблонах «grep -E» и должны использовать «[{]» для соответствия буквальному «{».
GNU grep -E пытается поддерживать традиционное использования, предполагая, что «{» не является специальным, если он в начале неверного обозначения интервала. Например, команда «grep -E ‘{1’» ищет двухсимвольную строку «{1» вместо сообщения об ошибке синтаксиса в регулярном выражении. POSIX позволяет это поведение как расширение, но портативные скрипты должны избегать этого.
Переменные окружения grep
Поведение grep подвергается воздействию следующими переменными окружения.
Локаль для категории LC_foo определяется исследованием трёх переменных окружения LC_ALL, LC_foo, LANG в этом самом порядке. Первая из этих установленных переменных определяет локаль. Например, если LC_ALL не установлена, а LC_MESSAGES установлена на pt_BR, то для категории LC_MESSAGES используется локаль Brazilian Portuguese. Локаль C используется если ни одна из этих переменных окружения не установлена, если каталог локали не установлен или если grep не была скомпилирована с поддержкой национальных языков (NLS). Команда оболочки
locale -a
выводит список доступных в данный момент локалей.
Многие из последующих переменных позволяют вам контролировать подсветку используя терминалом или эмулятором терминала командный интерпретатор Select Graphic Rendition (SGR). Смотрите раздел Select Graphic Rendition (SGR) в документации используемого текстового терминала чтобы узнать разрешённые величины и их значение в качестве символьных атрибутов. Эти значения подстрок являются целыми числами в десятеричном представлении и могут быть объединены точкой с запятой. grep отвечает за сборку результата в полную SGR последовательность («33[»…«m»). Популярные значения для объединения включают «1» для полужирного, «4» для подчёркивания, «5» для мерцания, «7» для инверсии, «39» для цвета переднего плана по умолчанию, с «30» по «37» для цветов переднего плана, с «90» по «97» для цветов переднего плана 16-цветного режима, с «38;5;0» по «38;5;255» для цветов переднего плана 88-цветного и 256-цветного режимов, «49» для стандартного фонового цвета, с «40» по «47» для фоновых цветов, с «100» по «107» для фоновых цветов 16-цветного режима и с «48;5;0» по «48;5;255» для фоновых цветов 88-цветного и 256-цветного режимов.
Двухбуквенные имена, используемые в переменной окружения GREP_COLORS (и некоторых других), относятся к терминальным «возможностям», способности терминала выделять текст или изменять его цвет и т. д. Эти возможности хранятся в онлайн-базе данных и доступны через библиотеку terminfo.
GREP_OPTIONS
Эта переменная указывает опции по умолчанию, которые будут помещены перед остальными явно указанными опциями. Поскольку это приводит к проблемам при написании портативных скриптов, эта возможность должна быть удалена в будущих выпусках grep и grep выводит предупреждения, если она используется. Пожалуйста, используйте псевдоним или скрипт вместо неё. Например, если grep в директории «/usr/bin», вы можете добавить $HOME/bin в ваш PATH и создать выполнимый скрипт $HOME/bin/grep, содержащий следующее:
#! /bin/sh export PATH=/usr/bin exec grep —color=auto —devices=skip «$@»
GREP_COLOR
Эта переменная определяет цвет, используемый для подсветки (не пустого) совпадающего текста. Она является устаревшей, на её смену пришла GREP_COLORS, но всё ещё поддерживается. mt, ms, и mc возможности GREP_COLORS имеют над ней приоритет. Она может определять только цвет, используемый для подсветки не пустого текста в любой подошедшей строке (выбранной строки когда пропущена опция командной строки -v, или контекстной строки, когда указана -v). Значением по умолчанию является 01;31, что означает полужирный красный текст переднего плана на стандартном фоне терминала.
GREP_COLORS
Определяет цвета и другие атрибуты, используемые в подсветке различных частей вывода. Её значение является разделённый двоеточием список возможностей, который по умолчанию установлен в ms=01;31:mc=01;31:sl=:cx=:fn=35:ln=32:bn=32:se=36 с пропущенными булевыми возможностями rv и ne (т.е. установленными на false). Поддерживаются следующие возможности.
sl=
Подстрока SGR для полных выбранных строчек (т.е. совпавших строк, когда пропущена опция командной строки -v или не-совпавшие строчки, когда указана -v). Тем не менее, если булева возможность «rv» и опция командной строки -v обе установлены, вместо этого она применяется к контексту совпавших строк. По умолчанию является пустой (т.е. стандартная цветовая пара терминала).
cx=
Подстрока SGR для полных контекстных строк (т.е. не-совпавших строчек, когда пропущена опция командной строки -v или совпавших строк, когда указана -v). Тем не менее, если булева возможность «rv» и опция командной строки -v обе установлены, то вместо этого она применяется к выбранным не-совпадающим строкам. По умолчанию является пустой (т.е. стандартная цветовая пара терминала).
rv
Булево значение, которое меняет местами значения возможностей sl= и cx= когда указана опция командной строки -v. Значение по умолчанию false (т.е. возможность пропущена).
mt=01;31
Подстрока SGR для совпавшего не пустого текста в любой совпавшей строчке (т.е. выбранной строчке, когда пропущена опция командной строки -v или строчка контекста, когда указана -v). Её настройка эквивалентная одновременной настройке двух ms= и mc= на одну величину. Значением по умолчанию является полужирный красный текст переднего плана поверх текущего фона строчки.
ms=01;31
Подстрока SGR для совпавшего не пустого текста в совпавшей строчке. (Используется только если пропущена опция командной строки -v). Эффект возможности sl= (или cx= если rv) остаётся активным, когда это имеет эффект. По умолчанию полужирный красный текст переднего плана поверх текущего фона строки.
mc=01;31
Подстрока SGR для совпавшего не пустого текста в контекстной строчке. (Используется только если указана опция командной строки -v). Эффект возможности cx= (или sl= если rv) остаётся активным, когда это имеет эффект. По умолчанию полужирный красный текст переднего плана поверх текущего фона строки.
fn=35
Подстрока SGR для имён файлов, добавляемых перед строчкой контента. По умолчанию это пурпурный цвет текста переднего плана поверх стандартного фона терминала.
ln=32
Подстрока SGR для номеров, добавляемых перед строчкой контента. По умолчанию это зелёный текст переднего плана поверх стандартного фона терминала.
bn=32
Подстрока SGR для добавляемого байтового сдвига перед строкой контента. По умолчанию это зелёный текст поверх стандартного фона терминала.
se=36
Подстрока SGR для разделителей, которые вставляются между выбранными полями (:), между полями строки контекста (-) и между группами примыкающих строк, когда указан ненулевой контекст (—). По умолчанию это текст цвета циан поверх стандартного фона терминала.
ne
Булево значение, которое предотвращает очистку цвета до конца строки используя Erase in Line (EL) to Right (33[K) каждый раз, когда заканчивается окрашенный элемент. Это нужно на терминалах без поддержки EL. В других случаях полезно на терминалах, для которых возможность back_color_erase (bce) boolean terminfo неприменима, когда выбранные цвета подсветки не имеют эффекта на фон, или когда EL слишком медленная или вызывает слишком много мерцаний. По умолчанию установлена на false (т.е. возможность пропущена).
Помните, что булевы возможности не имеют часть no =… По умолчанию они пропускаются (т.е. их значение false) и становится включаются (становятся true) когда указывается их имя.
LC_ALL, LC_COLLATE, LANG
Эти переменные определяют локаль для категории LC_COLLATE, которая определяет последовательность сортировки, используемой при интерпретации диапазона выражений вроде [a-z].
LC_ALL, LC_CTYPE, LANG
Эти переменные определяет локаль для категории LC_CTYPE, которая определяет тип символов, например, какие символы являются белыми пробелами. Эта категория также определяет кодировку символов, т.е. кодировка текста UTF-8, ASCII или какая-то другая кодировка. В локали C или POSIX все символы кодируются одним байтом и каждый байт является валидным символом.
LC_ALL, LC_MESSAGES, LANG
Эти переменные определяют локаль для категории LC_MESSAGES, которая определяет язык, который grep использует для сообщений. По умолчанию локаль C использует сообщения на американском английском.
POSIXLY_CORRECT
Если установлена, grep ведёт себя как требует POSIX; в противном случае grep ведёт себя больше как другие GNU программы. POSIX требует, чтобы опции, которые следуют за именами файлов, должны трактоваться как имена файлов; по умолчанию, такие опции переставляются вперёд списка операндов и трактуются как опции. Также POSIX требует, чтобы опции без категорий, которые диагностировались как «нелегальные», по умолчанию диагностировались бы как «невалидные», поскольку они не против закона. POSIXLY_CORRECT также отключает описанный ниже _N_GNU_nonoption_argv_flags.
_N_GNU_nonoption_argv_flags_
(Здесь N – это цифровой ID процесса программы grep.) Если i-ный символ значения этой переменной окружения равен 1, не считать i-ный операнд grep опцией, даже если он является единственным. Шелл может размещать эту переменную в окружение для каждой команды, которую он запускает, определяя, какие операнды являются результатом расширением подстановочных символов имени файла и поэтому не должны трактоваться как опции. Это поведение доступно только с библиотекой GNU C и только когда не установлена POSIXLY_CORRECT.
Статус выхода
Обычно статус выхода равняется 0 если выбрана строчка, 1 если строчка не выбрана и 2 если случилась ошибка. Тем не менее, если используется -q или —quiet или —silent и выбрана строка, то статусом выхода будет 0 даже если произошла ошибка.
Примеры использования grep
Примеры команды запуска grep:
grep -i ‘hello.*world’ menu.h main.c
Это выводит список всех строк в файлах menu.h и main.c, которые содержат строку «hello», за которой следует строка «world»; .* означает ноль или более любых символов, т.е. между «hello» и «world» могут содержаться любые символы и эта строка будет считаться соответствующей шаблону. Опция -i говорит grep игнорировать регистр букв, что приводит к тому, что строка «Hello, world!», которая в противном случае не соответствовала, также будет считаться подходящей.
Далее несколько популярных вопросов и ответов об использовании grep с примерами вызова этой программы.
1. Как можно вывести список только имён файлов, в которых найдено совпадение?
grep -l ‘main’ *.c
выведет имена всех C файлов в текущей директории, чей контент упоминает «main».
2. Как рекурсивно искать по директориям?
grep -r ‘hello’ /home/gigi
поиск ‘hello’ во всех файлах в директории /home/gigi. Для дополнительного контроля за файлами для поиска, используйте find, grep и xargs. Например, следующая команда делает поиск только по файлам C:
find /home/gigi -name ‘*.c’ -print0 | xargs -0r grep -H ‘hello’
Она отличается от этой команды:
grep -H ‘hello’ *.c
которая только ищет «hello» во всех файлах в текущей директории, чьё имя заканчивается на «.c». Команда выше «find …» более похожа на команду:
grep -rH —include=’*.c’ ‘hello’ /home/gigi
3. Что если шаблон начинается с «-»?
grep -e ‘—cut here—‘ *
ищет все строки, совпадающие с «—cut here—». Без -e, grep будет пытаться разобрать «—cut here—» как список опций.
4. Допустим я хочу искать по целому слову, а не по части слова?
grep -w ‘hello’ *
ищет только экземпляры «hello» которые являются целым словом; она не найдёт «Othello». Для большего контроля используйте «<» и «>» для совпадения начала и конца слов. Например:
grep ‘hello>’ *
ищет только слова, оканчивающиеся на «hello», поэтому оно будет соответствовать слову «Othello».
5. Как я могу вывести контекст вокруг совпадающих строк?
grep -C 2 ‘hello’ *
печатает две строки контекста вокруг подошедшей строки.
6. Как принудить grep печатать имя файла?
Добавьте /dev/null:
grep ‘mial’ /etc/passwd /dev/null
даст вам:
/etc/passwd:mial:x:1000:100::/home/mial:/bin/bash
Альтернативно используйте -H, которая является расширением GNU:
grep -H ‘mial’ /etc/passwd
7. Почему используют странное регулярное выражение для вывода ps?
ps -ef | grep ‘[c]ron’
Если бы шаблон был написан без квадратных кавычек, то он бы соответствовал не только ps выводу для cron, но также строке ps вывода для grep. Обратите внимание, что на некоторых платформах ps ограничивает вывод на ширину экрана; grep не имеет каких-либо лимитов на длину строки, кроме доступной памяти.
8. Почему grep пишет «Двоичный файл совпадает» («Binary file matches»)?
Если grep выводит все совпавшие «строки» из бинарного файла, она, вероятно, сгенерирует вывод, который бесполезен и даже может испортить вид. Поэтому GNU grep подавляет вывод из файлов, которые кажутся бинарными файлами. Чтобы заставить GNU grep выводить строки даже из файлов, которые похожи на бинарные, используйте опцию -a или «—binary-files=text». Для устранения сообщения «Двоичный файл совпадает», используйте опцию -I или «—binary-files=without-match».
9. Почему «grep -lv» не печатает файлы без совпадений?
«grep -lv» выводит имена всех файлов, содержащих одну или более строк, которые не совпадают. Для вывода имён всех файлов, которые не содержат совпадающие строки, используйте опцию -L или —files-without-match.
10. Я могу делать «ИЛИ» с «|», а что насчёт «И»?
grep ‘paul’ /etc/motd | grep ‘franc,ois’
найдёт все строки, которые содержат и «paul» и «franc,ois».
11. Почему пустой шаблон соответствует каждой строке ввода?
Команда grep ищет строчки, которые содержат строки, соответствующие шаблону. Каждая строчка содержит пустую строку, поэтому пустой шаблон приводит к тому, что grep находит соответствие на каждой строке. Не только пустой шаблон, также «^» (каждая строка имеет начало), «$» (каждая строка имеет окончание), «.*» (соответствует чему угодно) и многие другие шаблоны делают так, что grep находит совпадение в каждой строке.
Для совпадения с пустыми строками используйте шаблон «^$». Для совпадения с чистыми строками, используйте шаблон «^[[:blank:]]*$». Чтобы не было найдено ни одного совпадения, используйте команду «grep -f /dev/null».
12. Как я могу искать одновременно в стандартном вводе и в файлах?
Используйте специальное имя файла «-»:
cat /etc/passwd | grep ‘alain’ — /etc/motd
13. Как выразить палиндромы в регулярных выражениях?
Это можно сделать используя обратные сслыки; например, палиндром из четырёх символов:
grep -w -E ‘(.)(.).21’ файл
Это будет соответствовать слову «radar» или «civic».
Поиск палиндромов из пяти букв в стандартном словаре:
grep -w -E ‘(.)(.).21’ /usr/share/dict/american-english
Guglielmo Bondioni предложил единое регулярное выражение, которое находит все палиндромы до 19 символов длинной, используя 9 подвыражений и 9 обратных ссылок:
grep -E ‘^(.?)(.?)(.?)(.?)(.?)(.?)(.?)(.?)(.?).?987654321$’ файл
14. Почему эта обратная ссылка не работает?
echo ‘ba’ | grep -E ‘(a)1|b1’
Здесь ничего не будет выведено, поскольку первая альтернатива «(a)1» не имеет совпадений, ведь во вводе отсутствует «aa», из-за этого «1» во второй альтернативе не на что ссылаться, что означает, что она также не будет совпадать. В этом примере вторая альтернатива может совпасть только если совпала первая альтернатива – делая вторую излишней.
15. Как можно искать совпадения сразу по нескольким строкам?
Стандартная grep не может делать это, поскольку в своей основе её работа основана на построчной обработке. Следовательно, просто использование класса символов [:space:] не обработает новую строку (newline) тем способом, как вы могли бы ожидать.
С опцией -z (—null-data) GNU grep, каждый ввод и вывод «строчки» разделён символом null; смотрите Остальные опции. Следовательно, вы можете составлять регулярные выражения с использования символа новая строка (newline), но обычно если имеется совпадение, то будет выведен весь ввода, следовательно, это использование часто комбинируется с опциями, подавляющими вывод, такой как -q, например:
printf ‘foonbarn’ | grep -z -q ‘foo[[:space:]]+bar’
Если это недостаточно, вы можете трансформировать ввод перед передачей его в grep, или задействуйте awk , sed , perl или любые другие утилиты, которые предназначены для работы через строки.
Команда Grep для поиска определенной строки внутри файла
Команда Grep в основном используется для поиска строки по содержимому файла.. Также, есть возможность найти строку внутри регистра.
Для поиска строки Linuxvsem следует запустить команду ниже.
grep Linuxvsem name.txt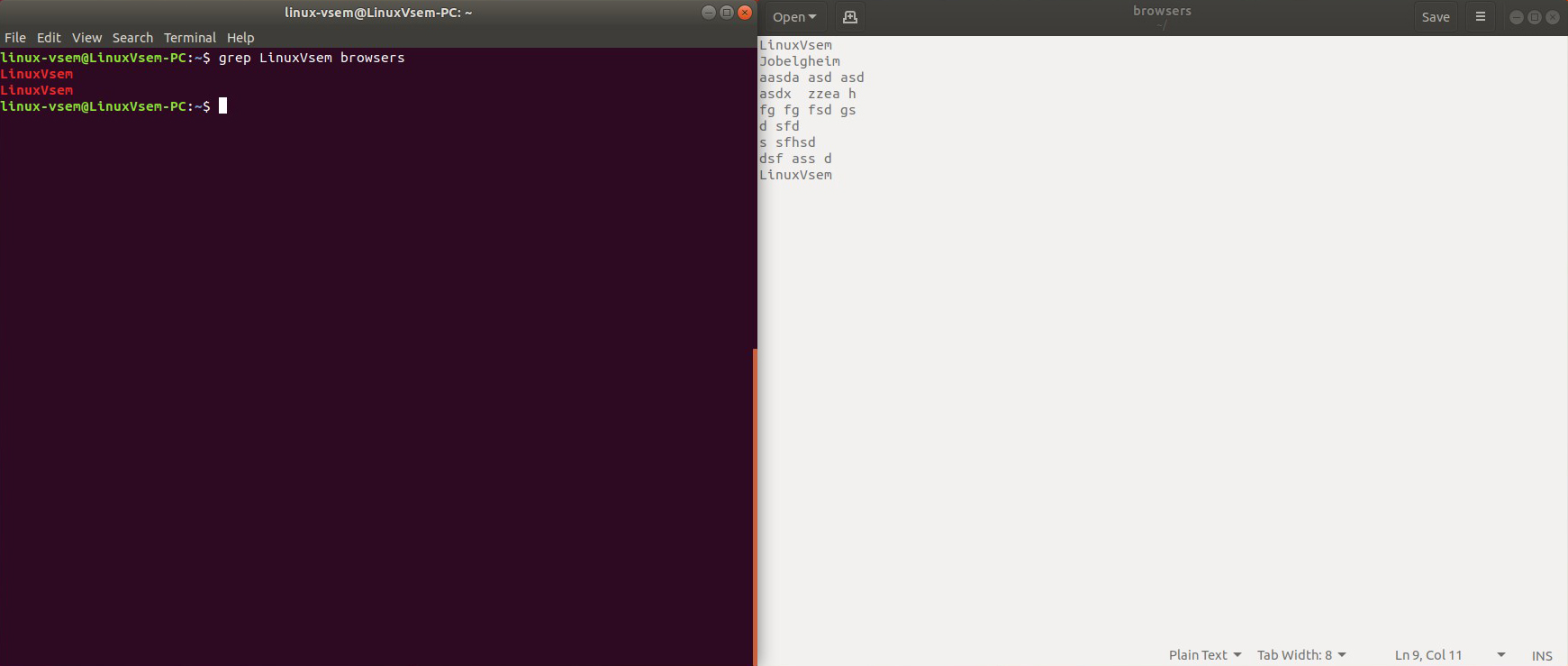
Если вы хотите выполнять поиск без учета регистра, запустите grep команду с опцией -i.
grep -i Linuxvsem name.txt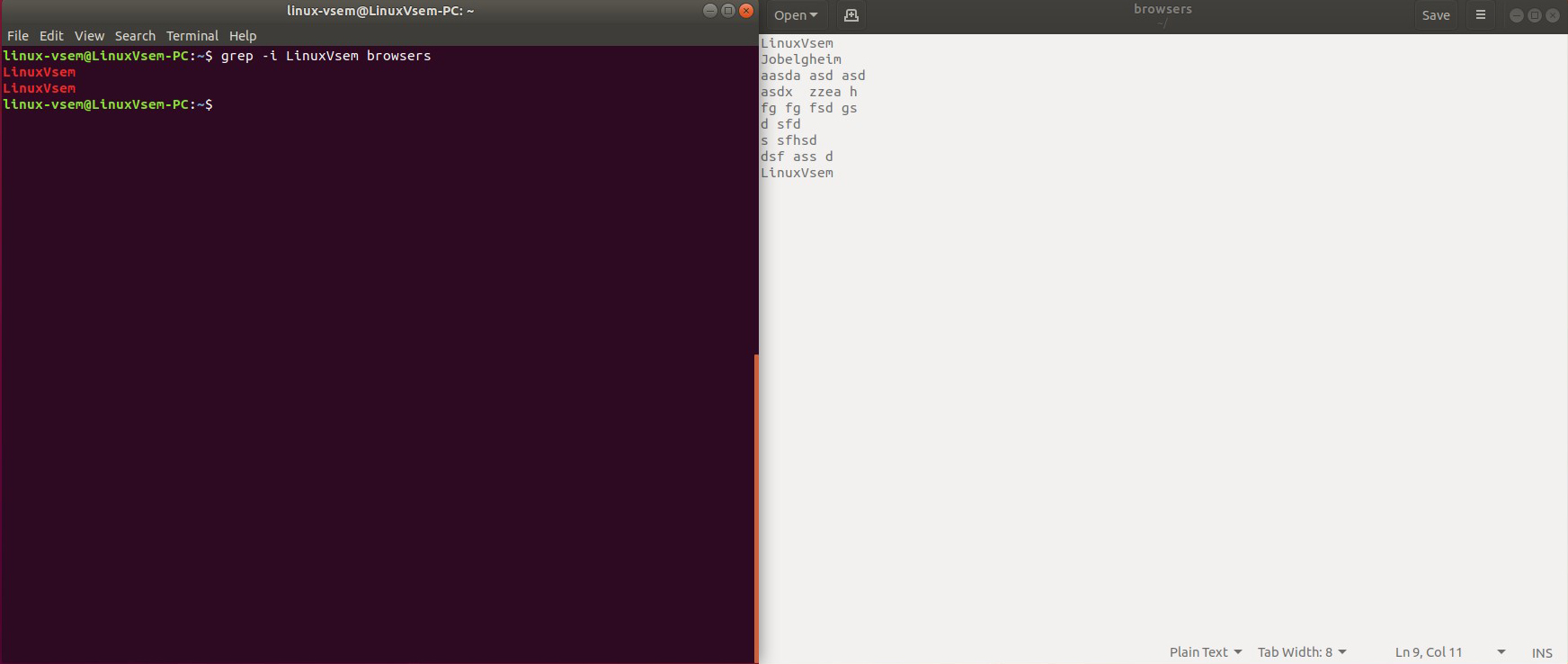
Если строка, которую вы хотите найти, содержит пробелы, их следует заключить в кавычки.
grep -i «Linuxvsem vins» name.txt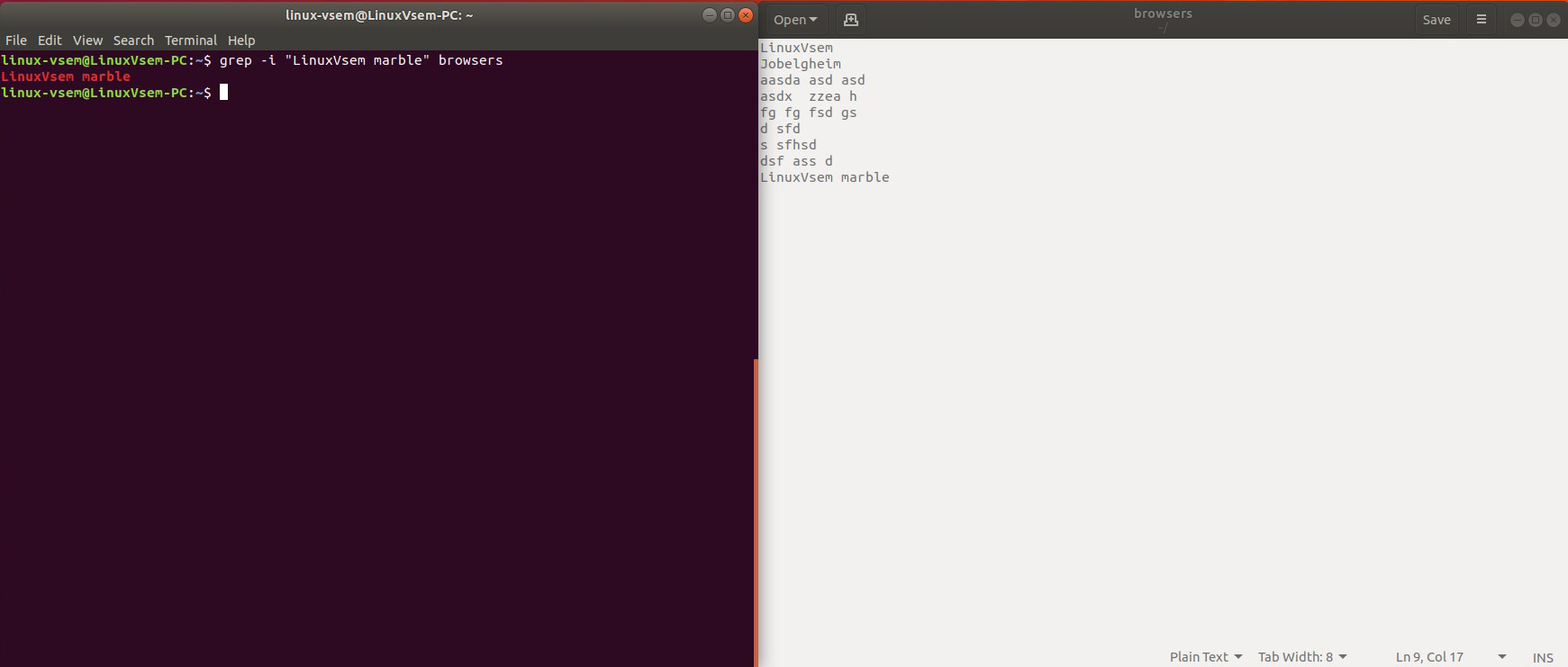
Количество совпадающих линий
Вы можете отобразить количество совпадающих строк, используя команду grep с -. В итоге, выполнив следующую команду, вы найдете количество строк Linuxvsem в names.txt файле:
grep -c Linuxvsem name.txt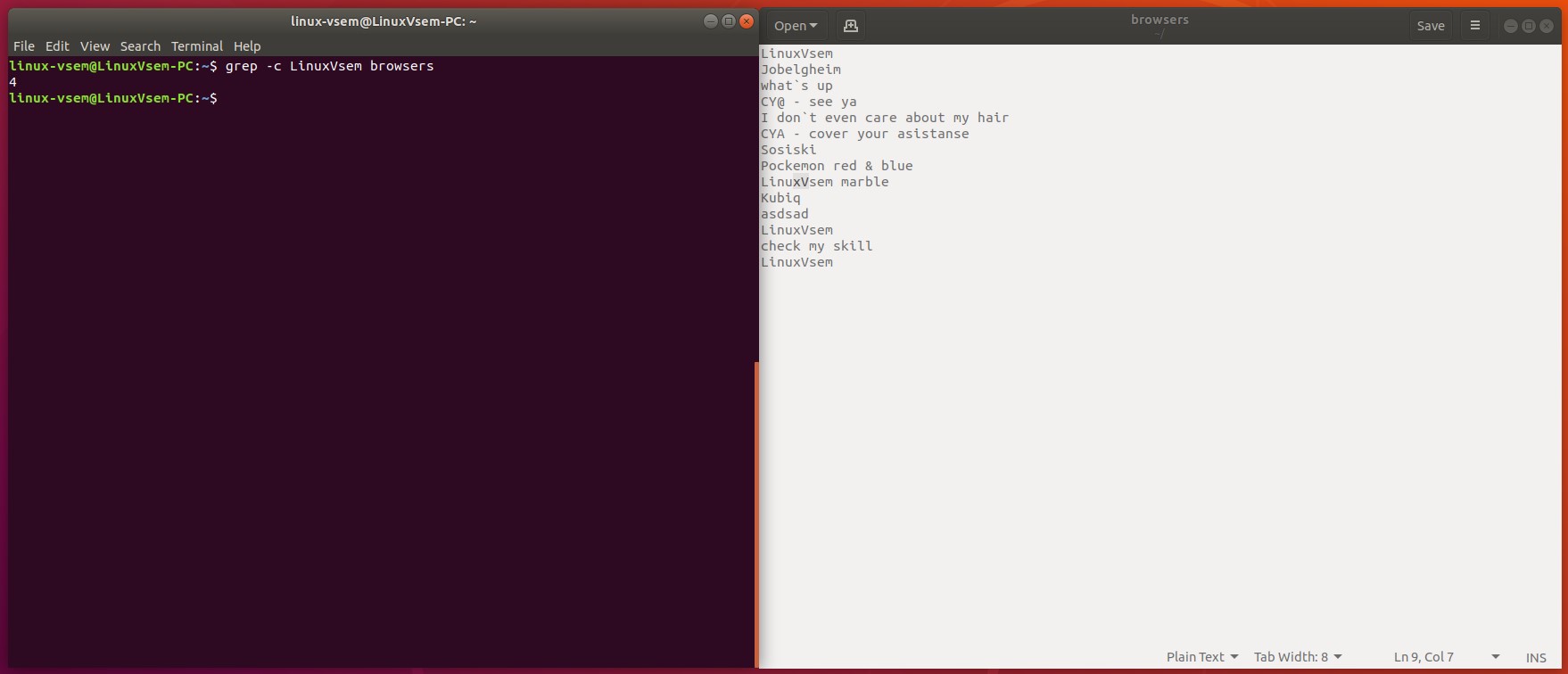
Инвертирование совпадений в команде Grep
Параметр Invert match ( -v) используется для инвертирования вывода grep. Команда отобразит строки, которые не соответствуют заданному шаблону.
Чтобы отобразить строки, которые не совпадают со строкой Linuxvsem в файле names.txt, выполните следующую команду.
grep -v Linuxvsem name.txt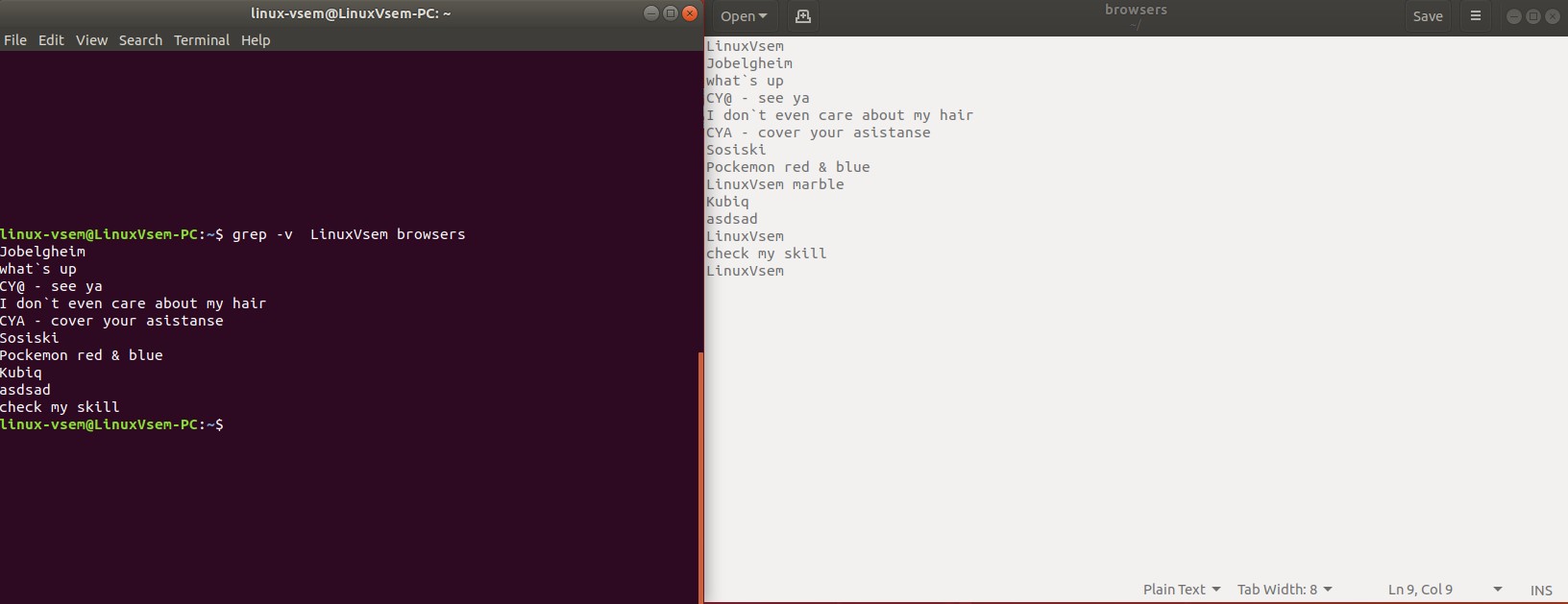
Основной синтаксис для команды grep
cat
grep
1. Простой поиск в файле
Давайте рассмотрим пример в файле “/etc/passwd” для поиска строки в файле. Чтобы найти слово “system” при помощи команды grep, используйте команду:
[root@destroyer ~]# cat /etc/passwd|grep system
Пример вывода:
systemd-bus-proxy:x:899:897:systemd Bus Proxy:/:/sbin/nologin
systemd-network:x:898:896:systemd Network Management:/:/sbin/nologin
2. Подсчет появления слов.
В приведенном выше примере мы имеем в системе поиск слов в файле “/etc/passwd”. Если мы хотим знать количество или число появлений слова в файле, то используйте опцию ниже:
[root@destroyer ~]# cat /etc/passwd|grep -c system
2
[root@destroyer ~]#
Выше указанно, что слово появилось два раза в файле “/etc/passwd”.
3. Игнорировать регистрозависимые слова
Команда grep чувствительна к регистру, это означает, что он будет искать только данное слово в файле. Чтобы проверить эту функцию, создайте один файл с именем «test.txt» и с содержанием, как показано ниже:
[root@destroyer tmp]# cat test.txt
AndreyEx
andreyex
ANDREYEX
Andreyex
[root@destroyer tmp]#
Теперь, если вы попытаетесь найти строку «andreyex», то команда не будет перечислять все слова «andreyex» с разными вариантами, как показано ниже:
[root@destroyer tmp]# grep andreyex test.txt
andreyex
[root@destroyer tmp]#
Этот результат подтверждает, что только один вариант будет показан, игнорируя остальную часть слова «andreyex» с разными вариантами. И если вы хотите игнорировать этот случай, вам нужно использовать параметр «-i» с grep, как показано ниже:
[root@destroyer tmp]# grep -i andreyex test.txt
AndreyEx
andreyex
ANDREYEX
Andreyex
4. Две разные строки внутри файла с командой grep
Теперь, если вы хотите найти два слова или строки с помощью команды grep, то вы должны задать расширенные. В следующей команде мы находим две строки «system» и «nobody» в файле /etc/passwd.
[root@destroyer ~]# egrep ‘system|nobody’ /etc/passwd
nobody:x:89:89:Nobody:/:/sbin/nologin
systemd-bus-proxy:x:899:897:systemd Bus Proxy:/:/sbin/nologin
systemd-network:x:898:896:systemd Network Management:/:/sbin/nologin
[root@destroyer ~]#
Рекурсивный поиск
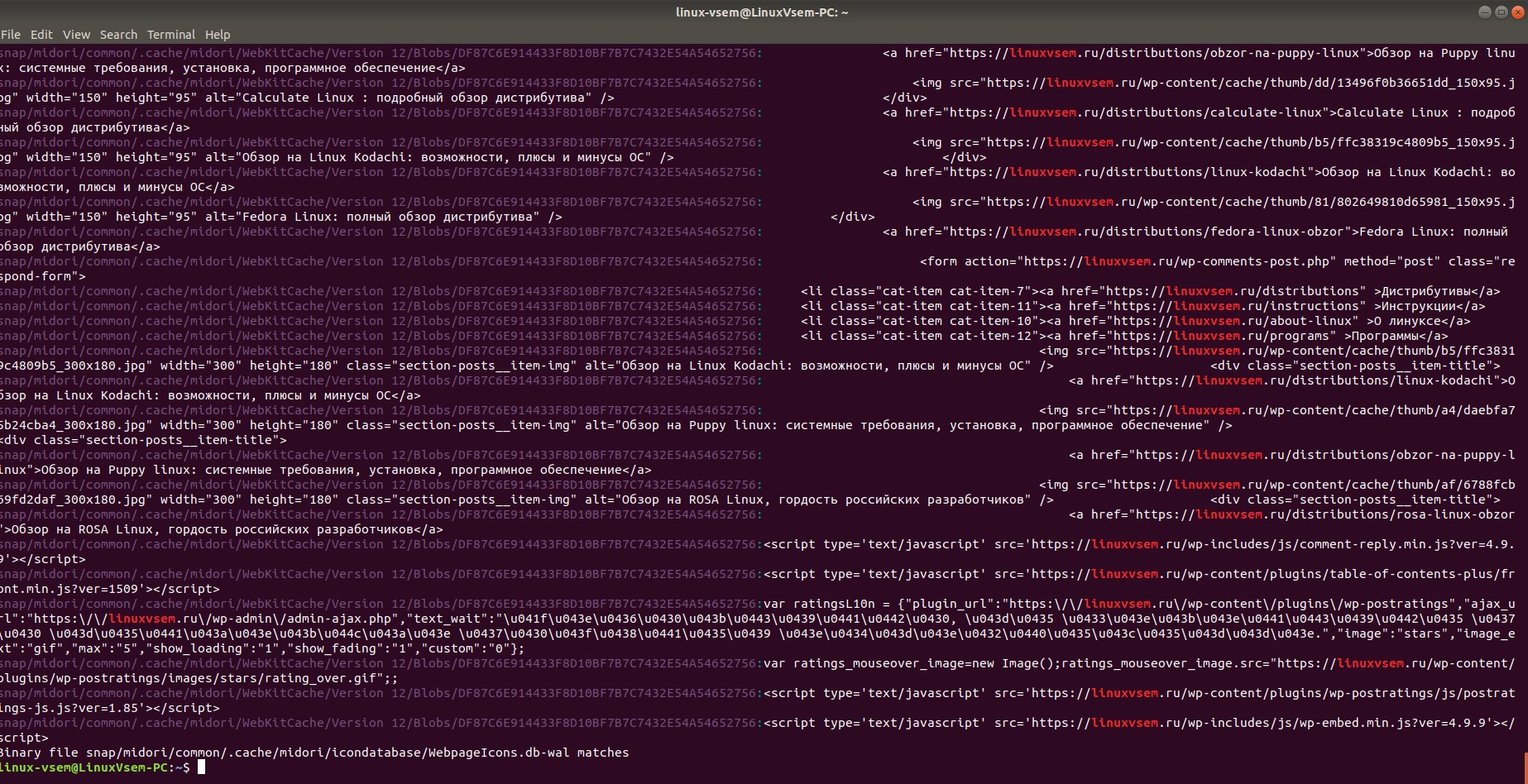
Для поиска заданной строки во всех файлах внутри каталога -rиспользуется опция -recursive.
В приведенном ниже примере строка «Linuxvsem» будет найдена во всех файлах внутри каталога linux:
grep -r Linuxvsem / Documents/ linux
Используя опцию, -R вы также можете искать файлы символьных ссылок внутри каталогов:
grep -R Linuxvsem / Документы / linux
Для поиска строки во всех каталогах вы можете запустить следующую команду:
grep -r » Linuxvsem » *
Строка поиска в стандартном выводе
Если необходимо найти строку в выводе команды — это можно сделать, комбинируя команду grep с другой командой.
Например, чтобы найти строку inet6 в выводе команды, ifconfig выполните следующую команду:
ifconfig | grep inet6
Полезные примеры Grep
Давайте разберём несколько практических примеров команды grep.
Игнорировать регистр
Мы можем заставить grep игнорировать различия в регистрах в шаблонах и данных. Например, когда я ищу «bar», соответствую «BAR», «Bar», «BaR»
$ grep -i ‘bar’ /path/to/file
В этом примере я собираюсь включить все подкаталоги в поиск:
$ grep -r -i ‘main’ ~/projects/
Как я могу посчитать строку, когда слова совпали
Команда grep может сообщить, сколько раз шаблон был сопоставлен для каждого файла, используя -c (count) опцию:
$ grep -c ‘word’ /path/to/file
Передайте -n опцию, которая должна предшествовать каждой строке вывода с номером строки в текстовом файле, из которого он был получен:
$ grep -n ‘root’ /etc/passwd
1:root:x:0:0:root:/root:/bin/bash 1042:rootdoor:x:0:0:rootdoor:/home/rootdoor:/bin/csh 3319:initrootapp:x:0:0:initrootapp:/home/initroot:/bin/ksh
ДЛЯ ЧЕГО МЫ ПОЛЬЗУЕМСЯ GREP-ОМ?
Grep это утилита командной строки Linux, который даёт пользователям возможность вести поиск строки. С его помощью можно даже искать конкретные слова в файле. Также можно передать вывод любой команды в grep, что сильно упрощает работу во время поиска и траблшутинга.
Возьмём команду ls. Сама по себе она выводит список всех файлов и папок.

вывод ls без grepвывод ls без grep
Но если нужно найти конкретную папку или один файл среди сотни других, то мы можем передать вывод команды ls в grep через вертикальную черту (|), а уже grep-у параметром передать нужное слово.
$ ls | grep Documents
ls с использованием grep
Если команда grep ничего не вернула, значит искомого файла/папки не существует в данной директории.
grep без результатов
- https://blog.debian-help.ru/2015/03/grep-poisk-v-linux-primeri
- https://ZaLinux.ru/?p=1270
- https://lumpics.ru/linux-grep-command-examples/
- https://linuxvsem.ru/commands/grep-linux
- https://bloglinux.ru/2563-polnoe-rukovodstvo-komanda-grep-v-linux.html
- https://www.hostinger.com.ua/rukovodstva/komanda-grep-v-linux
- https://infoit.com.ua/linux/ubuntu/kak-ispolzovat-komandu-grep-v-linux/
- https://zen.yandex.ru/media/merion_networks/rukovodstvo-po-komande-grep-v-linux-5e4a4ffc6e1cd54e7a5cb471
